![[レポート]PostgreSQL上の生成AIアプリでベクトル検索するためのベストプラクティス #DAT423 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]PostgreSQL上の生成AIアプリでベクトル検索するためのベストプラクティス #DAT423 #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWSのPostgreSQLの Principal Product Manager - Technicalを務めるJonathan Katzさんによるセッション"DAT423 | Best practices for querying vector data for gen AI apps in PostgreSQL"をレポートします。

本セッションは、PostgreSQLをベクトルデータベース化する pgvector エクステンションを題材に、検索品質の評価では、再現率(recall)が何よりも大事といったベクトルデータベースのベストプラクティスが、具体的な実験結果とともに展開されました。
以下のスクリーンショットはYouTube動画からのものです。
セッション情報
- スピーカー
- Jonathan Katz(Principal Product Manager - Technical, AWS)
- タイトル
- DAT423 | Best practices for querying vector data for gen AI apps in PostgreSQL
- 概要
- PostgreSQL makes it easier to store and query vector data for artificial intelligence and machine learning (AI/ML) use cases with the pgvector extension. Learning best practices for vector search will help you deliver a high-performance experience to your customers. In this session, learn how to store data from Amazon Bedrock in an Amazon Aurora PostgreSQL-Compatible Edition database and learn SQL queries and tuning parameters to optimize the performance of your application when working with AI/ML data, vector data types, exact and approximate nearest neighbor search algorithms, and vector-optimized indexing.
- 動画 : https://www.youtube.com/watch?v=L8fQqVwTT3Y
- スライド : https://reinvent.awsevents.com/content/dam/reinvent/2024/slides/dat/DAT423_Best-practices-for-querying-vector-data-for-gen-AI-apps-in-PostgreSQL.pdf
セッションのハイライト
生成AIアプリでは、RAGを始めとしてモデルを利用したベクトル化(埋め込み)とベクトルを対象とした検索が求められます。
ベクトル検索では、ベクトルを元にベクトルの集合に対して検索します。
大量のベクトル同士を比較すると、計算量が膨れ上がるため、Approximate Nearest Neighbor(ANN) という近似アルゴリズムが用いられます。
このアルゴリズムはあくまでも近似のため、取りこぼしがあります。
正解10個のうち8個を当てられたら、再現率(recall)は80%です。

ベクトル検索を評価するときに
- 再現率
- インデックスの構築時間
- クエリーパフォーマンス(スループット、レイテンシー)
などが気になります。

Katzが言うには、 再現率が何よりも大事 、ということです(動画 9:09)。
いくらスループットが良くても、再現率が0%(空振っている)だと意味がありません。
pgvector のベクトル検索用インデックス
pgvector が実装している ANN はクラスターベースの IVFFlatと グラフベースの HNSW の2種類がトレードオフの関係にあります。現在は、後から実装された HNSW のほうがうまくいくことが多く、主流になりつつあります。

selectivity とインデックスの選択
ベクトル検索ならベクトル検索用インデックスを使うべしと思考停止してしまいがちですが、一部のデータを対象にベクトル検索する場合、つまり、selectivity が高い場合、B-Tree のような古典的なインデックスでフィルタリングしたあとで、ベクトル同士を比較したほうが早いです。
pgvector HNSWは m が大事
以降では、pgvectorのHNSWインデックスを題材に様々な実験結果やトレードオフ関係が解説されます。
HNSWインデックスでは重要なパラメータが2つあります
- m
- the max number of connections per layer
- デフォルトは16
- ef_construction
- the size of the dynamic candidate list for constructing the graph
- デフォルトは64
例えば、動画28:55 では、Katzが最もお気に入りのスライドが紹介されています。
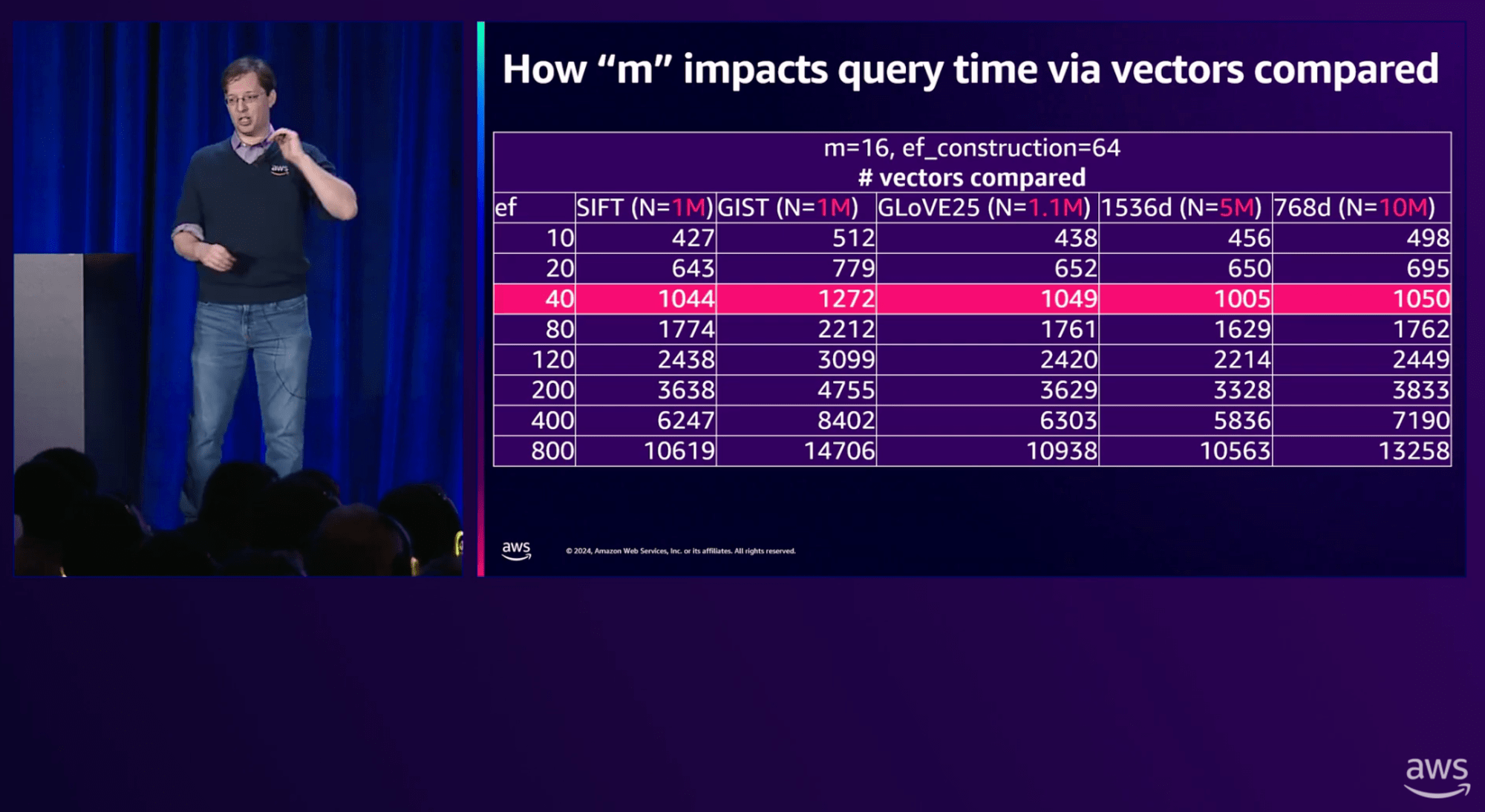
5つの埋込モデルで検索時間を評価すると、データ数がそれぞれ異なるにも関わらず、評価候補のベクトルの数が同程度に抑えられています。
m=16としているおかげです。
まとめ
セッションタイトルからはRAG のベストプラクティスのような内容を期待しますが、PostgreSQL を ベクトルデータベース 化する pgvector エクステンションの HNSW インデックス を題材にした、データベース、特に、インデックス周りを深掘った、密度の濃いセッションとなっています。
データベースに興味があるなら、視聴をおすすめします。










